SFB 1309

ProteomicsDB: a multi-omics and multi-organism resource for life science research
2019-10-30
Patroklos Samaras, Tobias Schmidt, Martin Frejno, Siegfried Gessulat, Maria Reinecke, Anna Jarzab, Jana Zecha, Julia Mergner, Piero Giansanti, Hans-Christian Ehrlich, Stephan Aiche, Johannes Rank, Harald Kienegger, Helmut Krcmar, Bernhard Kuster, Mathias Wilhelm
Nucleic Acids Research, 2020, Vol. 48, Database issue D1153–D1163
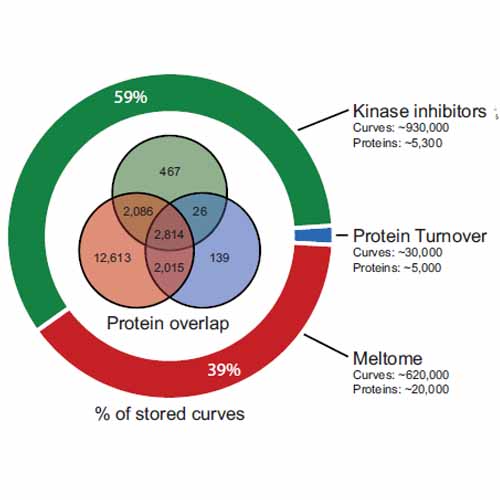
ProteomicsDB (https://www.ProteomicsDB.org) started as a protein-centric in-memory database for the exploration of large collections of quantitative mass spectrometry-based proteomics data. The data types and contents grew over time to include RNA-Seq expression data, drug-target interactions and cell line viability data. In this manuscript, we summarize new developments since the previous update that was published in Nucleic Acids Research in 2017. Over the past two years, we have enriched the data content by additional datasets and extended the platform to support protein turnover data. Another important new addition is that ProteomicsDB now supports the storage and visualization of data collected from other organisms, exemplified by Arabidopsis thaliana. Due to the generic design of ProteomicsDB, all analytical features available for the original human resource seamlessly transfer to other organisms. Furthermore, we introduce a new service in ProteomicsDB which allows users to upload their own expression datasets and analyze them alongside with data stored in ProteomicsDB. Initially, users will be able to make use of this feature in the interactive heat map functionality as well as the drug sensitivity prediction, but ultimately will be able to use all analytical features of ProteomicsDB in this way.